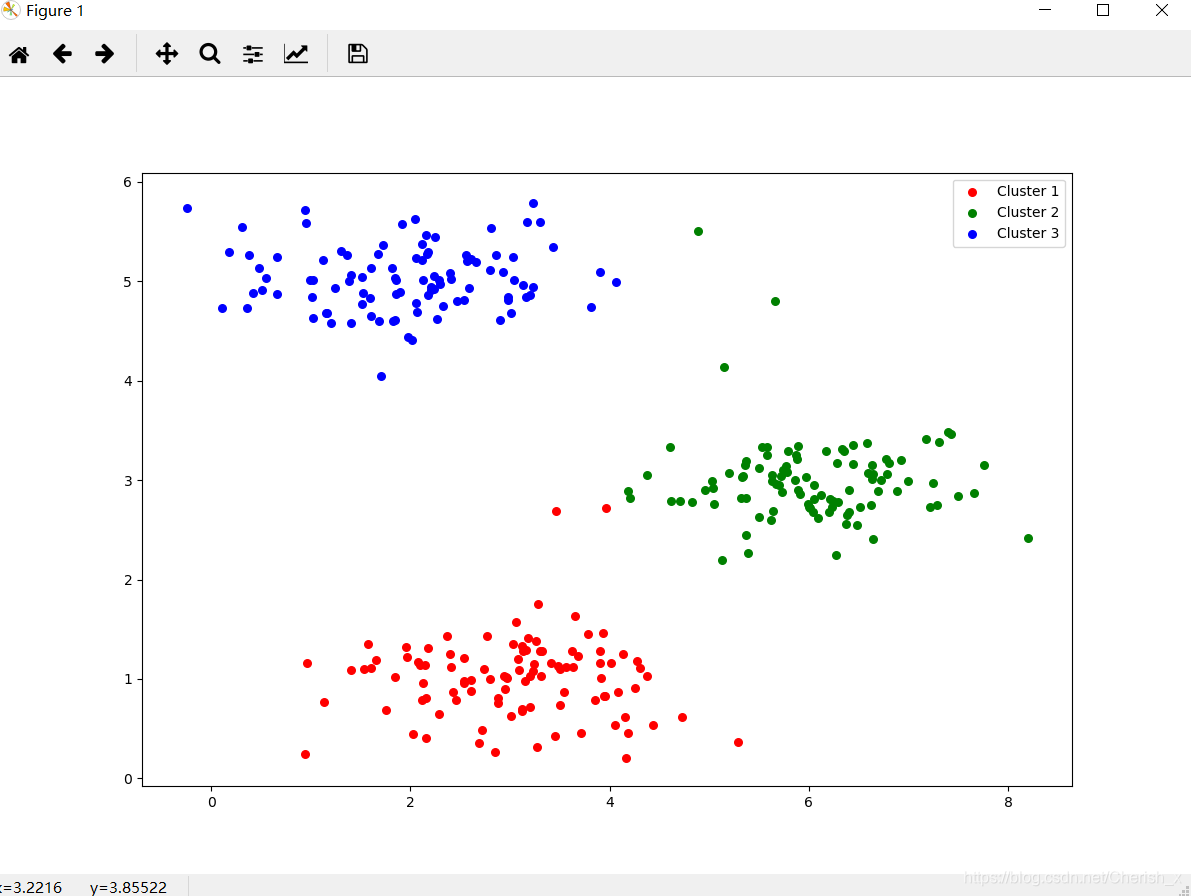
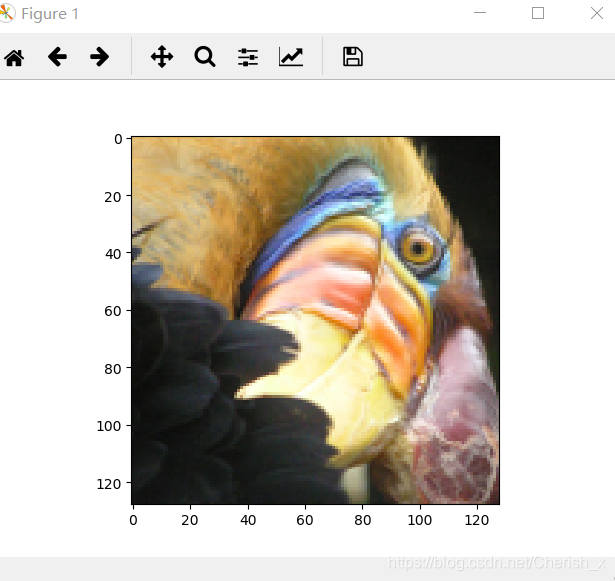
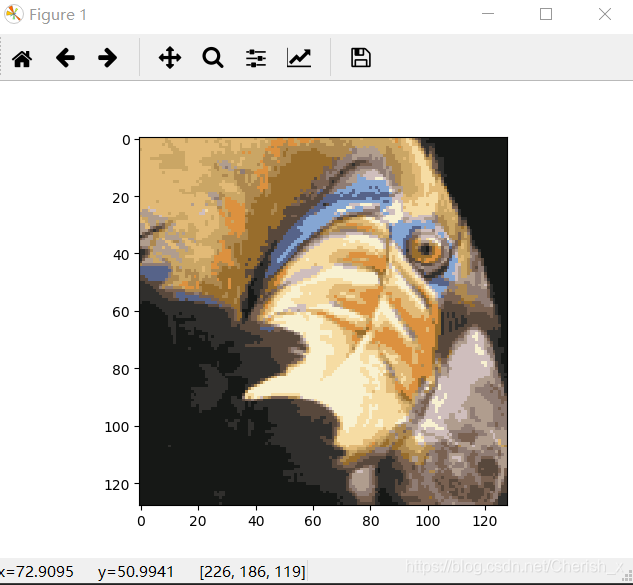
吴恩达《机器学习》——第七次作业:k-means算法 Posted on 2019-06-01 | Post modified: 2019-10-16 | In ML Words count in article: 478 | Reading time ≈ 2 2D-kmeans算法 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sbfrom scipy.io import loadmatdef find_closet_centroids(X, centroids): '''将每个特征计算属于那个特征''' m = X.shape[0] k = centroids.shape[0] idx = np.zeros(m) for i in range(m): min_dist = 1000000 for j in range(k): dist = np.sum((X[i, :] - centroids[j, :]) ** 2) if dist < min_dist: min_dist = dist idx[i] = j return idxdef compute_centroids(X, idx, k): '''更新聚类中心''' m, n = X.shape centroids = np.zeros((k, n)) for i in range(k): indices = np.where(idx == i) centroids[i, :] = (np.sum(X[indices, :], axis=1) / len(indices[0])).ravel() return centroidsdef run_one_kmeans(X, initial_centroids, max_iters): '''运行k-means均值算法进行聚类''' m, n = X.shape k = initial_centroids.shape[0] idx = np.zeros(m) centroids = initial_centroids for i in range(max_iters): idx = find_closet_centroids(X, centroids) centroids = compute_centroids(X, idx, k) return idx, centroidsdef init_centroids(X, k): '''随机初始化聚类中心''' m, n = X.shape centroids = np.zeros((k, n)) idx = np.random.randint(0, m, k) for i in range(k): centroids[i, :] = X[idx[i], :] return centroidsdef run_all_kmeans(X, k, n_init, max_iter): '''kmeans算法''' min_dist = 1000000 m, n = X.shape result_centroids = np.zeros((k, n)) result_idx = np.zeros(m) cnt = 0 for i in range(n_init): initial_centroids = init_centroids(X, k) # #print(initial_centroids) idx, centroids = run_one_kmeans(X, initial_centroids, max_iter) dist = 0 for j in range(m): dist += np.sum((X[j, :] - centroids[int(idx[j]), :]) ** 2) / len(X) if dist < min_dist: min_dist = dist result_idx = idx result_centroids = centroids cnt = i #print(cnt) return result_idx, result_centroidsdata = loadmat('data/ex7data2.mat')X = data['X']idx, centroids = run_all_kmeans(X, 3, 30, 10)cluster1 = X[np.where(idx == 0)[0], :]cluster2 = X[np.where(idx == 1)[0], :]cluster3 = X[np.where(idx == 2)[0], :]fig, ax = plt.subplots(figsize=(12, 8))ax.scatter(cluster1[:, 0], cluster1[:, 1], s=30, color='r', label='Cluster 1')ax.scatter(cluster2[:, 0], cluster2[:, 1], s=30, color='g', label='Cluster 2')ax.scatter(cluster3[:, 0], cluster3[:, 1], s=30, color='b', label='Cluster 3')ax.legend()plt.show() k-means应用:图像压缩图像压缩前: 123456789101112131415161718192021222324252627from IPython.display import Imageimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sbfrom k_means_and_PCA.kmeans_2D import run_all_kmeansfrom scipy.io import loadmatImage(filename='data/bird_small.png')image_data = loadmat('data/bird_small.mat')A = image_data['A'] / 255X = np.reshape(A, (A.shape[0] * A.shape[1], A.shape[2]))idx, centroids = run_all_kmeans(X, 16, 10, 10)X_recovered = centroids[idx.astype(int), :]X_recovered = np.reshape(X_recovered, (A.shape[0], A.shape[1], A.shape[2]))X_recovered *= 255plt.imshow(X_recovered.astype(int))plt.show() 图像压缩处理后 : ------ 本文结束 ------