[toc]
1. EDA-数据探索
对数据进行EDA主要做的是对数据集的宏观分析, 我们要了解数据集的规模,查看数据的统计分布,了解特征之间的相关性等。
我们为什么要做EDA,是为了能够理解数据,所以在开始地时候,我们不能抱有某种偏见,要完全正直,或者把自己当作小白去看数据,一开始,如果你什么都不知道,是对的状态。
在数据可视化中,我们要尽量让简洁图呈现出重要的信息。
描述趋势使用折线图;
描述数量使用柱状图;
描述关系使用散点图;
描述比例使用饼状图;
本次学习使用天池数据挖掘入门级竞赛,二手车交易价格预测https://tianchi.aliyun.com/competition/entrance/231784/information
1.1 相关第三方包导入
1 | # 导入warnings包,利用过滤器实现忽略警告语句 |
pandas,numpy,matplotlib对于数据分析是非常常见的。本次任务中用到了两个新的库,seaborn,missingno,
seaborn:是基于matplotlib的一个可视化库,相当于对底层matplotlib做了一层封装,可以用它画出更加直观、吸引人的统计图形。
missingno:是一个用于缺失数据可视化和实用程序的小工具集,我们可以通过它直观的总结数据集的完整性。
1.2 载入数据
1 | # 载入数据 |
导入其他格式文件
| 文件格式 | 对应函数 |
|---|---|
| CSV文件 | pd.read_csv(filename) |
| Excel文件 | pd.read_excel(filename) |
| Mysql文件 | pd.read_sql(query, connection_object)+ |
| 文本文件 | pd.read_table(filename) |
read_csv()读文件默认是以逗号为分隔符,若是以其他分隔符,比如制表符/t,则需要在指定参数sep后加上指定的分隔符,本次数据集使用空格为分隔符。
1.3 观察数据
1.3.1 大体观察数据
1 | # 观察数据的前部分,默认是5个,可以加参数 |
1 | # 观察数据的后部分,默认是5个,可以加参数 |
1 | # 还可以将二者综合起来一起观察 |
1.3.2 观察数据维度
这一点十分重要,不然后面模型训练很麻烦。
1 | # 管擦数据的维度 |
1 | # 观察数据的列数 |
1 | # 观察数据的行数 |
测试数据同样要观察,这里不再赘述,下面的笔记也都是值对train做处理,记得test数据做同杨处理即可。
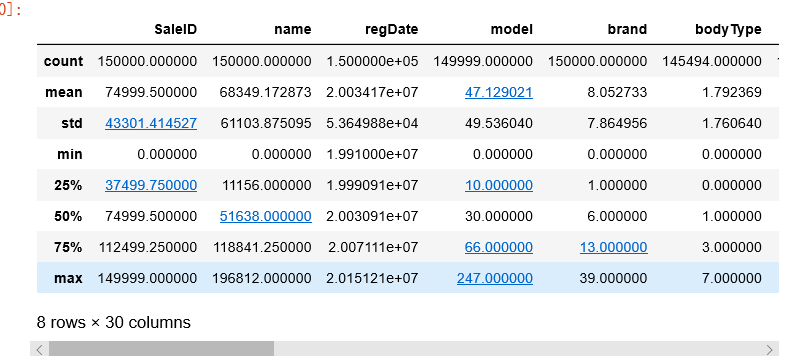
1.3.3 观察数据的一些相关统计量
例如总数,平均值,标准差,最小值,25%、50%、75%分数,最大值等。我们可以通过观察某些值提前选定某些异常值或缺失值。
1 | # 通过describe()来熟悉数据的相关统计量 |
1.3.4 通过info()来熟悉数据类型
1 | train_data.info() |

像本此数据,我们可以知道更多的都是数字类型,又可以细分为整型和浮点型,但是值得注意的是有一个数据类型是object。那这个object到底是个啥呢,看下表
| :pandas dtype | :-python类型 | :-numpy类型 | :-用途 |
|---|---|---|---|
| object | str | string, unicode | 文本 |
| int64 | int | int, int8, int16, int32, int64, uint8, uint16, uint32, uint64 | 整数 |
| float64 | float | float,float16,float32,float64 | 浮点数 |
| bool | bool | bool | 布尔值 |
| datetime64 | NA | NA | 日期时间 |
| timedelta[ns] | NA | NA | 时间差 |
| category | NA | NA | 有限长度的文本值列表 |
1.3.5 查看每列的存在的nan情况
1 | # 查看每列的存在nan情况 |
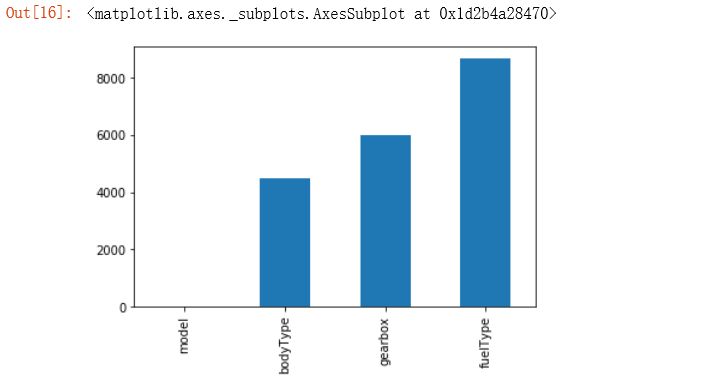
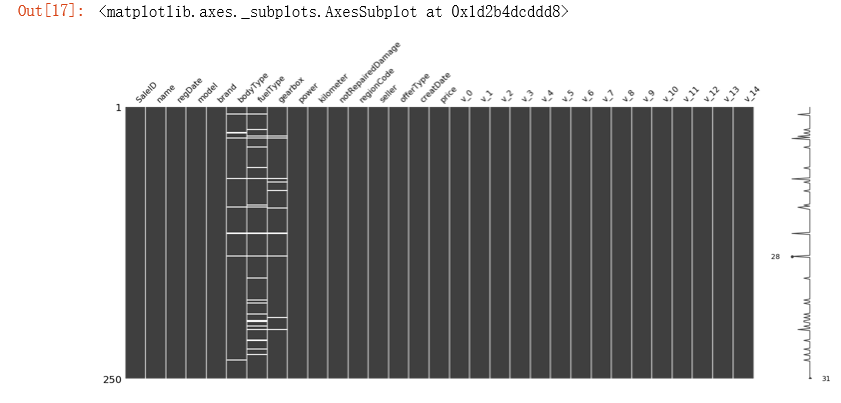
从这里我们可以知道数据集的某些特征有多少缺失值,对于缺失值的处理也十分重要。
1 | # 对缺失值可视化 |
- 如果缺失值的数量很小,一般选择进行填充,当然如果你使用
lgb等树模型,可以不做处理,模型会自动优化 - 如果缺失值的数量很大,过多,那么我们一般考虑将其删掉,观察模型的得分情况如何。
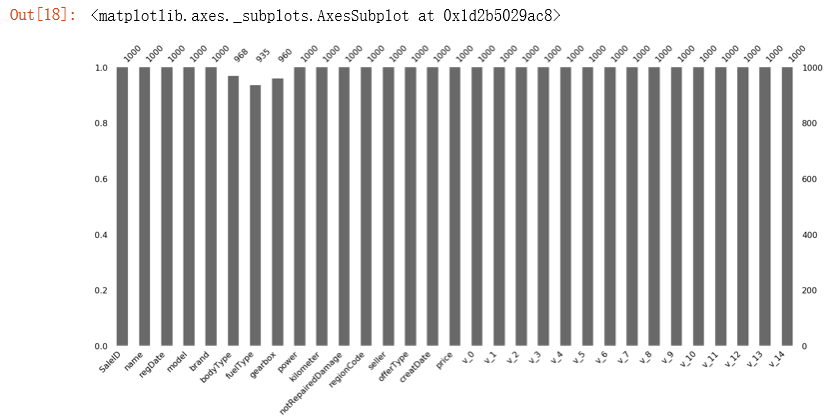
1 | # 可视化看下缺省值 |
1 | msno.bar(train_data.sample(1000)) |
1.3.6 异常值检测
从上面我们可以知道notRepairedDamage的数据类型不是数字,因此我们先来分析此特征。
1 | train_data['notRepairedDamage'].value_counts() |

可以看到该特征有个取值是’-‘,我们可以将其认为为缺失值,替换为nan
1 | # 将-替换为nan |
对于seller和offerType这两个特征严重倾斜,对预测结果的意义不大,因此我们可以直接将其删除掉。
1 | del train_data['seller'] |
1.3.7 了解预测值分布
1 | train_data['price'] |
我们通过观察预测值,可以知道这是一个分类任务还是回归任务,本此数据集,显然是一个回归任务。
1 | train_data['price'].value_counts() |
预测值的总体分布概况
1 | # 总体分布概况 |
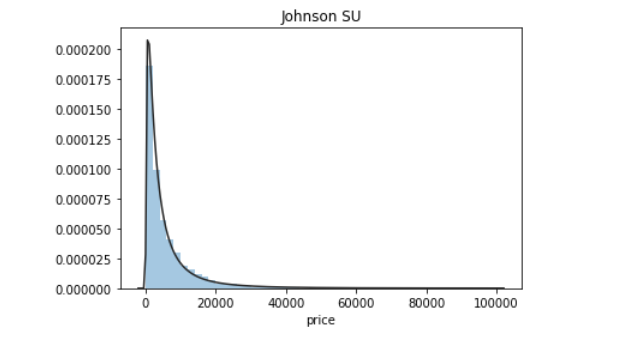
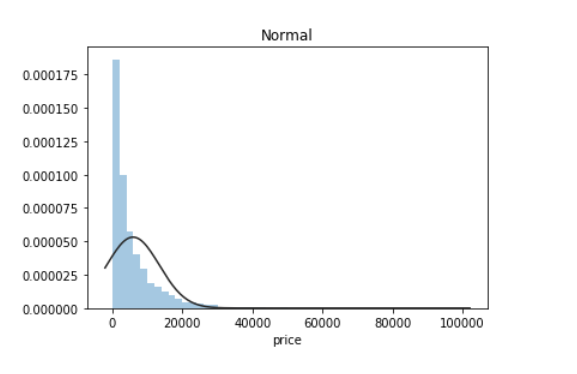
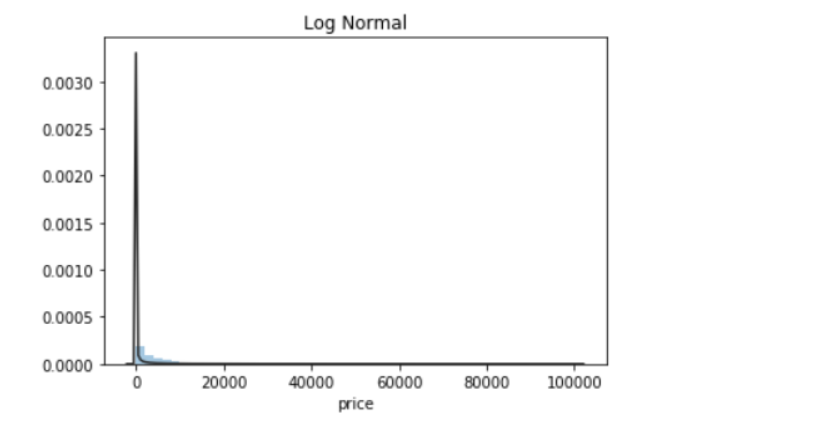
约翰逊分布是经过约翰变换后服从正态分布的随机变量的概率分布
displot()集合了matplotlib的hist()与核函数估计kdeplot的功能,增加了rugplot分布观测条显示与利用scipy库fit拟合参数分布的新颖功能
从图可以知道,价格很明显是不符合正态分布的,所在在进行回归之前,必须进行转换。最佳拟合无界约翰逊分布。
1 | # 查看预测值的具体频数 |
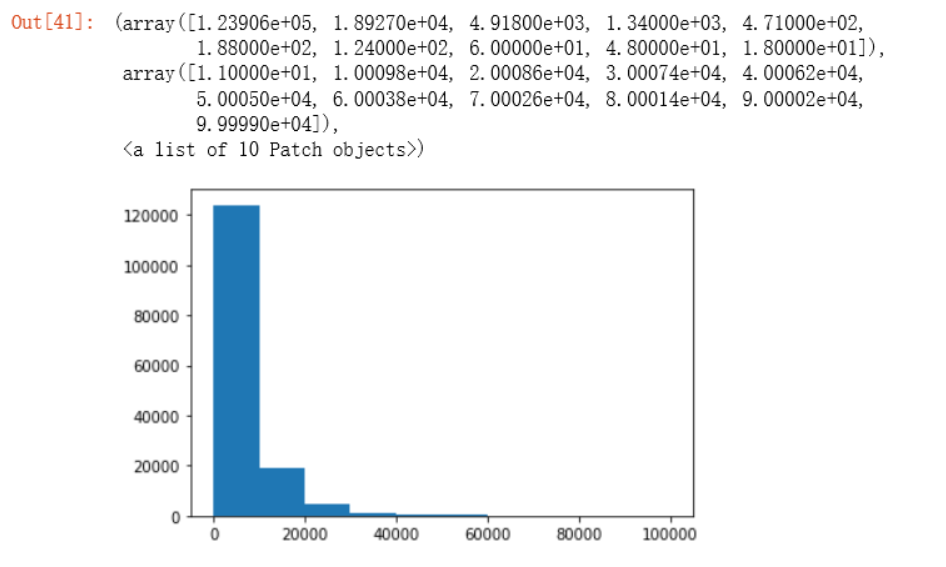
从图中可以看出0到20000的取值占了绝大部分。因此,我们在做模型训练的时候,可以将其视作一条规则。
1 | # 对数变换后观察分布、 |
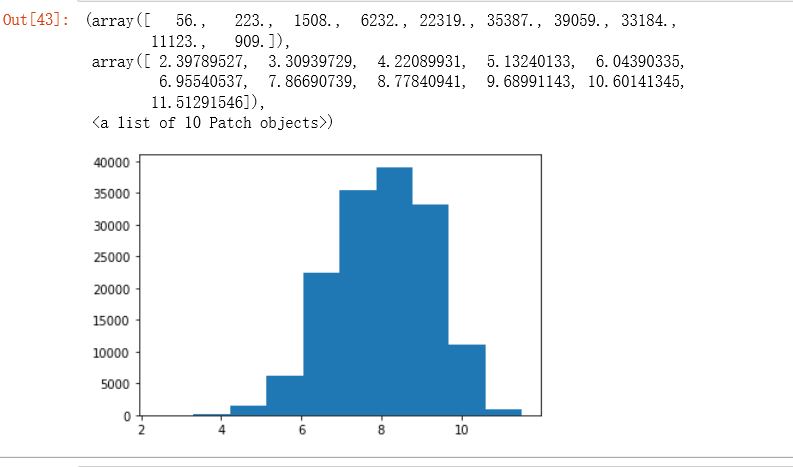
值得注意的是,经过对数变换后,分布较为均匀,有点正态分布的意思了。
1.3.7查看峰度和偏度
1 | # 查看偏度和峰度 |
偏度:偏度(skewness)也称为偏态、偏态系数,是统计数据分布偏斜方向和程度的度量,是统计数据分布非对称程度的数字特征
峰度:峰度(Kurtosis)与偏度类似,是描述总体中所有取值分布形态陡缓程度的统计量。这个统计量需要与正态分布相比较,峰度为0表示该总体数据分布与正态分布的陡缓程度相同;峰度大于0表示该总体数据分布与正态分布相比较为陡峭,为尖顶峰;峰度小于0表示该总体数据分布与正态分布相比较为平坦,为平顶峰。峰度的绝对值数值越大表示其分布形态的陡缓程度与正态分布的差异程度越大
1 | # 查看所有特征的峰度和偏度 |
1 | # 可视化偏度 |
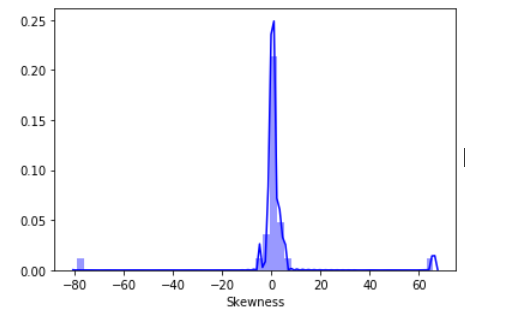
横坐标是偏度,纵坐标是该偏度值在总体 样本中占的百分比,从图中可以看出,-10~10的偏度更多一些,尤其是0附近的。
1 | # 可视化峰度 |
1.4 对特征分类观察分析
特征可以分类为数字特征和类别特征,这两者既有联系也有区别,我们需要将其分类观察分析。
1 | # 将特征进行分类 |
1.4.1 数字特征分析
1.4.1.1 相关性分析
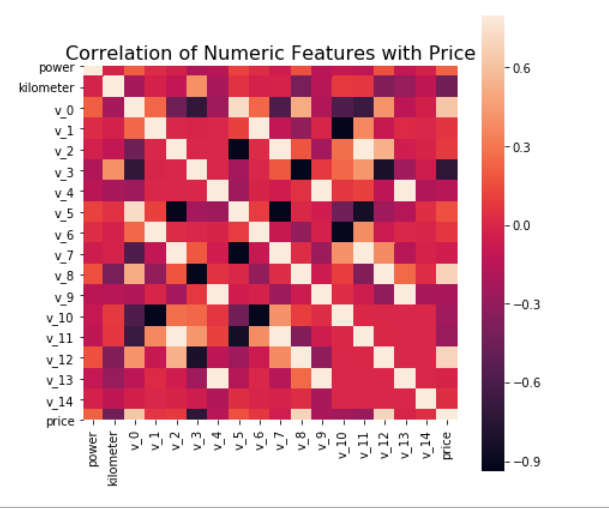
1 | # 观察数字特征和预测值的相关性 |
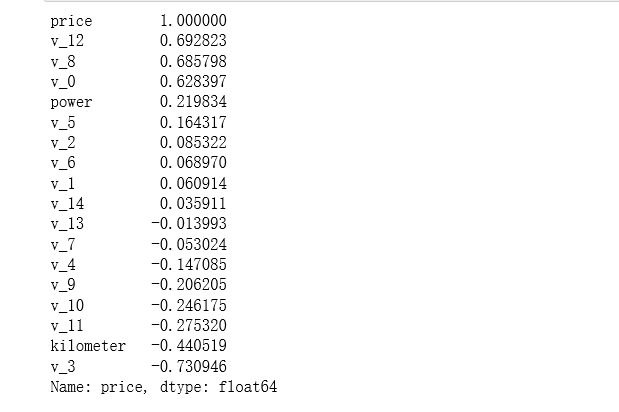
相关性分析是量化不同因素间变动状况一致程度的重要指标。相关程度高的特征是我们希望要的,因为相关程度越高,越说明该特征对预测结果更有帮助。
相关系数corr,取值在[-1,1]。corr值越大,不用因素之间的相关程度越高,负值表示负相关,正值表示正相关
算法有很多,最常用是Pearson相关系数,还有Spearman相关系数和Kendall相关系数
- Pearson相关系数
计算公式: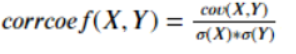
Numpy和Pandas都提供了Pearson相关系数的计算函数分别是np.corrcoef()和Pandas.corr()。
- 向量夹角余弦
把两组数据作为两个一维向量,通过计算两个向量的夹角余弦值,同样可以衡量数据的相关程度,取值范围在[-1,1]之间,
计算公式: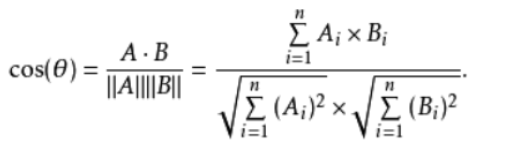
Spearman相关系数
Spearman相关系数又称秩相关系数,是利用两变量的秩次大小做相关性分析,对原始变量的分布不做要求,也没有线性要求。
Scipy的
spearmanr()函数可以计算Spearman相关系数Spearman相关系数有如下特点:
- 属于非参数统计方法,适用范围更广。
- 对于服从Pearson相关系数的数据亦可计算Spearman相关系数,但统计效能要低一些。
- 秩次:样本数据正向排序后的序号(从1开始)
kendall相关系数
肯德尔秩相关系数也是一种秩相关系数,但是他所计算的对象是分类有序/等级变量,比如考试名次等。
特点:
- 如果两组排名是相同的,系数为1 ,两个属性正相关。
- 如果两组排名完全相反,系数为-1 ,两个属性负相关。
- 如果两组排名是完全独立的,系数为0。
1 | # 两两特征间的相关性分析 |
1.4.1.2 数字特征分布可视化
1 | del price_numeric['price'] |
1 | # 每个数字特征的分布可视化 |
(图太长了,略略略)
我们可以从图得出一些结论,例如他在那几个主要的值分布的较多,后期,我们可以尝试做分箱处理。
1 | # 数字特征相互之间的关系可视化 |

我们可以根据特征之间的相关行,进行特征的筛选,如果两个特征呈现正相关,我们就应该删去一个特征以简化模型。
1 | # 多变量互相回归关系可视化 |
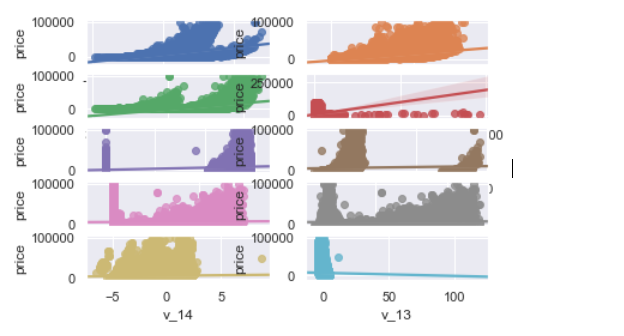
1.4.2 类别特征分析
1 | ## 2) 类别特征箱形图可视化 |
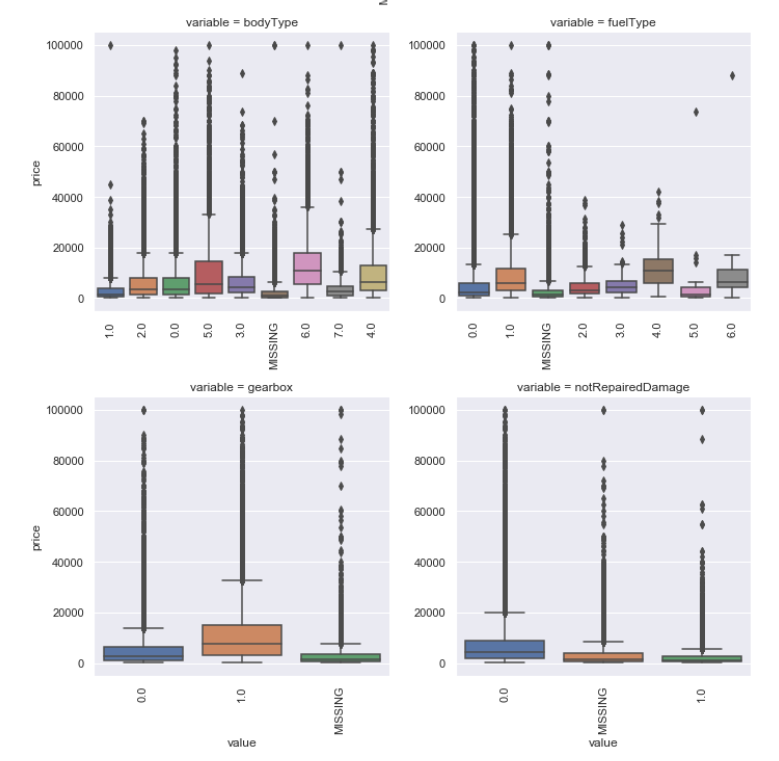
箱型图最大的优点就是不受异常值的影响,可以以一种相对稳定的方式藐视数据的离散分布情况,也利于数据的清洗。
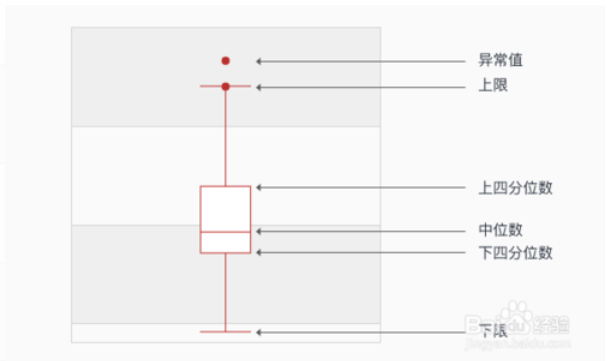
下四分位数Q1、中位数Q2、上四分位数Q3计算方法:Qi所在的位置=i*(n+1)/4
上限是非异常范围的最大值,四分位距IQR=Q3-Q1,那么上限=Q3 + 1.5IQR
下限是非异常范围的最小值,下限=Q1-1.5IQR
直观明了地识别数据批中的异常值
箱线图判断异常值的标准以四分位数和四分位距为基础,四分位数具有一定的耐抗性,就是多大25%的数据可以变的任意元而不会很大地扰动四分位数,所以异常值不会影响箱型图地数据形状。
利用箱线图判断数据集地偏态和尾重
异常值越多说明尾部越重,自由度越小。
偏态表示偏离程度,异常值集中在较小值一侧,则分布呈左偏态;异常值集中在较大值一侧,则分布 呈👉偏态。
1 | # 类别特征的小提琴图可视化 |
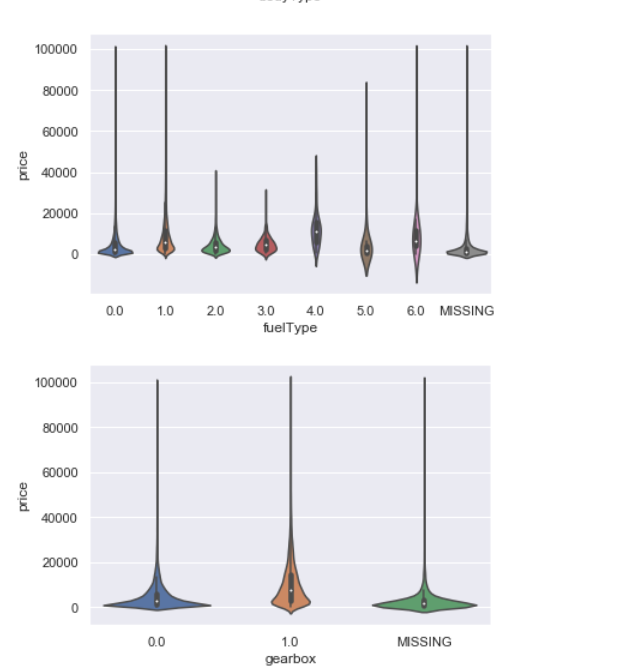
小提琴图用来展示类别变量地值地分布情况,宽的地方数据分布多。
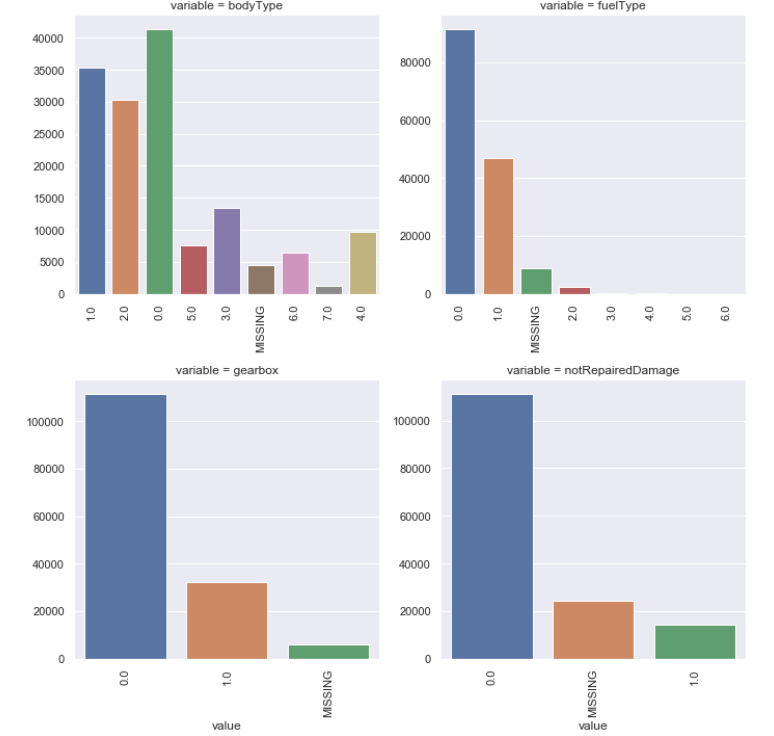
1 | # 类别特征的柱形图可视化 |
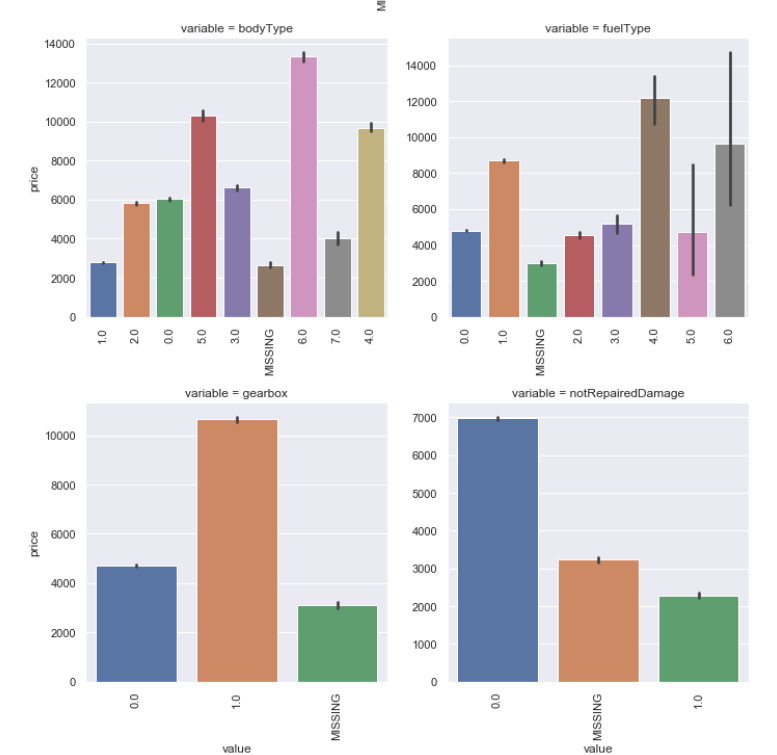
1 | # 类别特征的每个类别频数可视化 |