[toc]
2. 特征工程
常见的特征工程包括
1. 异常处理:
通过箱线图(或3-Sigma)分析删除异常值
3-Sigma:标准正态分布中99.73%的数据都在(u-3α,u+3α)之间,因此我们可以认为超过这个氛围的数据是异常的。
如果数据分布并不是正态分布,那么3-Sigma原则就不一定适用,当然如果近似正态分布,还是可以的。
因此箱线图是一种普适的方法,而3-Sigma的使用是有条件:正态分布或近似正态分布。
BOX-COX转换(处理有偏分布)
BOX-COX转换定义:线性回归模型满足线性、独立性、方差齐性以及正态性的同时,不丢失信息,此种变换为BOX-COX变换
对于有偏分布,通过BOX-COX转换为正态分布,再通过箱型图或3-Sigma处理
长尾截断
- 特征归一化/标准化
优点
标准化(转换为标准正态分布)
数据的标准化是将数据按比例缩放,使之落入一个小的特定的空间
标准差标准化:
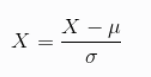
该方法适用于样本原始分布近似于高斯分布,归一化结果范围0~1
归一化(转换到[0,1]区间)
线性归一化:
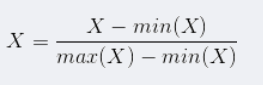
该方法适用于样本分布较为集中的时候,否则归一化结果不够稳定
针对幂律分布,可以采用公式
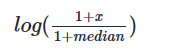
非线性归一化:使用log、tanh等,经常用在数据分化较大的场景,有些数值很大,有些很小,通过一些数学函数,将原始值进行映射。
- 数据分箱:
数据分箱是一种数据预处理技术,用于减少次要观察误差的影响,是一种将多个连续值分组为较少数量的分箱方法。这种对连续变量离散化后,模型会更稳定,同时也降低了模型过拟合的风险。
- 等频分箱:区间的边界要经过选择,使得每个区间包含大致相等的示例数量。
- 等距分箱:从最小值到最大值之间,均分为N等份,每个区间长度为
W=(max-min)/N。 - Best-KS分箱:
- 卡方分箱:自底向上的数据离散化方法。它依赖于卡方检验,将具有最小卡方值的相邻区间合并在一起,知道满足确定的停止准则。
- 缺失值处理:
- 不处理,如果使用LGB等树模型
- 删除,如果缺失数量太多
- 插值补全,包括均值/中位数/众数/建模预测/多重插补/压缩感知补全/矩阵补全等
- 利用先验知识填充
- 分箱,将缺失值单独分为一个箱
- 特征构造:
构造统计量特征,包括计数,求和,比例,标准差等一些统计量
时间特征,包括相对时间和绝对是件,节假日,双休日等
地理信息,包括分箱,分布编码等方法,
非线性变换,包括log/平发/根号等
特征组合,特征交叉
特征组合也叫做特征交叉,但是合成特征和特征组合不太一样,特称交叉可以理解为特征组合的一个子集。
合成特征:一种特征,不在输入特征之列,而是从一个或多个输入特征衍生而来。通过标准化或缩放单独创建的特征不属于合成特征。
包括以下几种类型:
1. 将一个特征与其本身或其他特征相乘 2. 两个特征相除 3. 对连续特征进行分箱。特称组合:通过将单独的特征进行组合(相乘或求笛卡尔积)而形成的合成特征。特征组合有助于表示非线性关系。
- 特征筛选:
过滤式(filter):按照发散性或相关性对各个特征进行评分,设定阈值或者待选择特征的个数进行筛选
基本想法: 分别对每个特征xi,计算xi相对于类别标签y的信息量S(i),得到n个结果。然后将n个S(i)按照从大到小排序,输出前k个特征。我们的目标是选取与y关联最密切的一些特征xi,那么使用什么样的方法来度量S(i)是一个关键问题。
主要有一下几种方法:
- Pearson相关系数
- 卡方验证
- 互信息和最大信息系数
- 距离相关系数
- 方差选择法
包裹式(wrapper): 根据目标函数(往往是预测效果评分),每次选择若干特征,或者排除若干特征
基本思想:基于hold-out方法,对于每一个待选的特征子集,都在训练集上训练一遍模型,然后在测试集上根据误差大小选择出特征子集。
贪婪搜索算法:是局部最优算法。与之对应的是穷举算法,穷举算法是遍历所有可能的组合达到全局最优,但是不太实际
- 前向搜索:每次增量的从剩余未选中的特征选出一个加入到特征集中,待达到阈值或者n时,从所有F中选出得分最高的特征集。
- 后向搜索:先将F设置为包含全部特征的特征集,然后每次增量的减去特征,直到达到阈值或者为空是,选择最佳的特征集。
- 递归特征消除法:使用一个基模型进行多轮训练,每轮训练后通过学习器返回的coef_或者feature_importances_消除哪些权重较底的特征,再基于新的特征集进行下一轮训练。
嵌入式(embedding):先使用某些机器学习的模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征(类似于Filter,只不过系数是通过训练得来的)
- 基于惩罚项的特征选择法 通过L1正则项来选择特征:L1正则方法具有稀疏解的特性,因此天然具备特征选择的特性。值得注意的是,L1没有选到的特征不代表不重要,原因是两个具有高相关性的特征可能只保留了一个,如果要确定哪个特征重要需要再通过L2正则方法交叉检验。
- 基于学习模型的特征排序 这种方法的思路是直接使用你要用的机器学习算法,针对每个单独的特征和响应变量建立预测模型。假如某个特征和响应变量之间的关系是非线性的,可以用基于树的方法(决策树、随机森林)、或者扩展的线性模型等。基于树的方法比较易于使用,因为他们对非线性关系的建模比较好,并且不需要太多的调试。但要注意过拟合问题,因此树的深度最好不要太大,再就是运用交叉验证。通过这种训练对特征进行打分获得相关性后再训练最终模型。
降维
如果你最后特征工程走一遍下来,特征很多的话,最后进行以下降维.
PCA/LDA/ICA
特征选择也是一种降维
2.1 前期准备
导入相关的第三方包
1 | import pandas as pd |
载入数据
1 | train_data = pd.read_csv('../data/used_car_train_20200313.csv', sep=' ') |
将训练数据与测试数据放在一起,方便处理
1 | train_data['train'] = 1 |
2.2 异常值处理
异常值处理更多是发生在数字特征上,而类别特征最多会出现倾斜的现象,一般这种情况是直接将该特征删除掉。所以,我们通过EDA直到可能会出现异常值的有power、kilemoter以及匿名特征。以power为例
1 | # 观察power的箱型图和柱形图 |
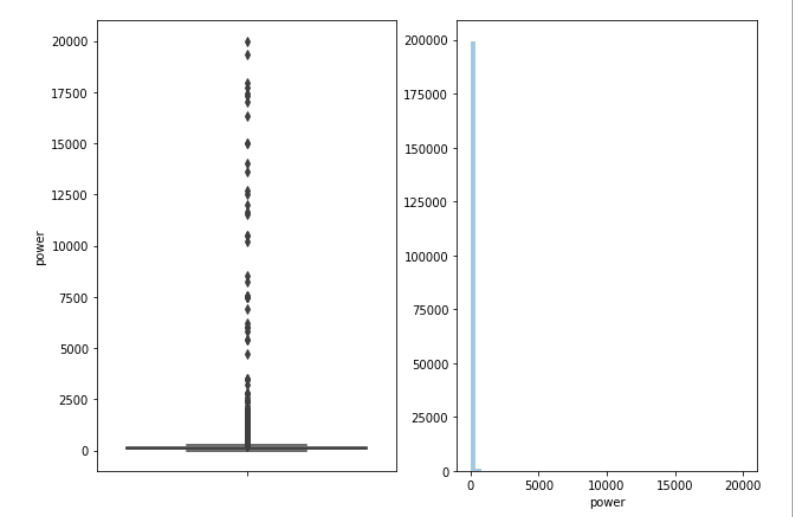
从箱型图可以看到缺失存在很多可以认为异常值的值,可以选择将其进行删除,但是现在我们是将训练数据和测试数据一起处理的,如果选择删除不免会将测试数据删除。因此这里我们可以采用用上限值替换异常值。
1 | def box_plot_outliers(data_ser, box_scale): |
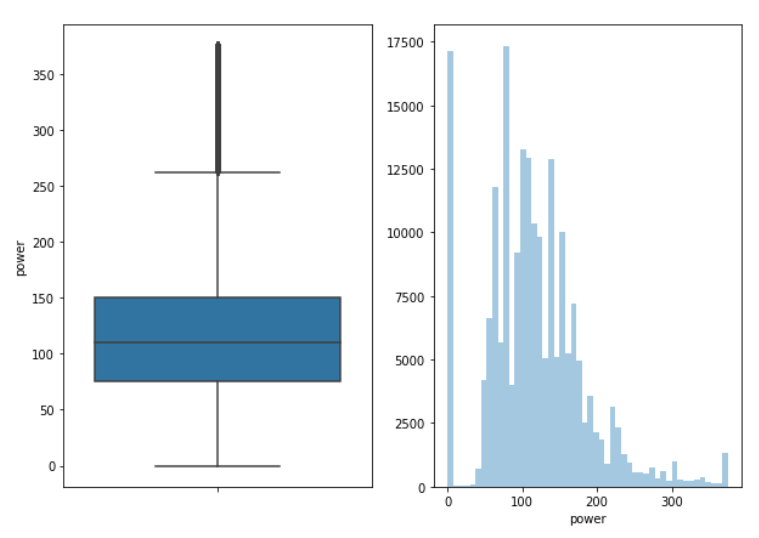
经过异常值处理后,好了很多。
本批数据也出现了数据倾斜的现象。直接将其删除,EDA里有记录的。
2.3 缺失值处理
我们通过EDA知道缺失值不算多,我们后期使用树模型,所以这里不做处理。
2.4 数据分箱
对车辆使用时间分箱
新车使用10年视为报废,把15%作为不折旧的固定部分为残值,其余85%为浮动折旧值。可分三个阶段:3年
4年3年来折旧,折旧率分别为11%、10%和9%,前三年每年折11%。计算公式为:评估价=市场现行新车售价×[15%(不动残值)+85%(浮动值)×(分阶段折旧率)]+评估值。
1 | # 使用时间:data['creatDate'] - data['regDate'],反应汽车使用时间,一般来说价格与使用时间成反比 |
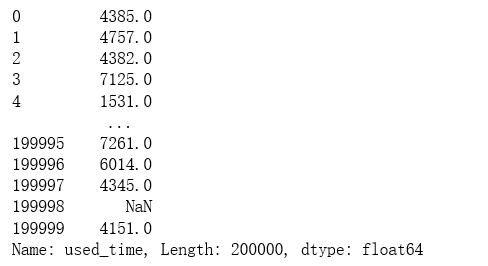
1 | used_time_bin = [0, 1068, 2492, 3560, 5340, 100000,np.nan] |
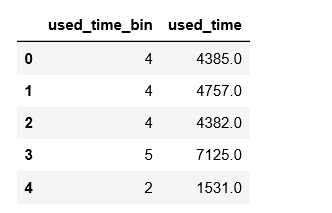
对车辆形势公里数分箱
具体为:一部车有效寿命30万公里,将其分为5段,每段6万公里,每段价值依序为新车价的5/15、4/15、3/15、2/15、1/15。假设新车价12万元,已行驶7.5万公里(5年左右),那么该车估值为12万元×(3+3+2+1)÷15=7.2万元。
1 | kilometer_bin = [0, 6, 12, 18, 24] |
对发动机功率分箱
1 | bin = [i*10 for i in range(31)] |
2.5 构造特征
1 | # 从邮编中提取城市信息,相当于加入了先验知识 |
城市的消费水平不同,必然,二手车的价格也就不同。
我们还可以通过计算训练集中品牌、车型的价格的统计量特征,将其作为特征加入到训练集和测试集中,这相当于加入了先验知识,让模型更好地拟合。
1 | # 品牌 |
1 | # 车身类型 |
匿名特征:有些比赛的特征是匿名特征,这导致我们并不清楚特征相互直接的关联性,这时我们就只有单纯基于特征进行处理,比如装箱,groupby,agg 等这样一些操作进行一些特征统计,此外还可以对特征进行进一步的 log,exp 等变换,或者对多个特征进行四则变换
1 | for i in range(0, 15): |
目前的数据已经可以给树模型使用了,所以先导出一下
1 | # 删除不需要的数据 |
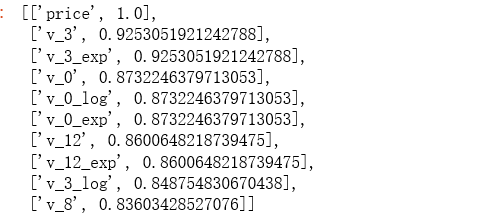
2.7 特征筛选
特征选择有三种方法,我选择了耗时最短也较为简单的过滤式。因为就如吴恩达老师说的,第一步是应该用短时间撸一个baseline出来。所以,另外两种形式,我撸完baseline再补充。
1 | # 过滤式 |