–真的没有图片–
非结构化数据的数据探索不像结构化数据,结构化数据可以通过数据探索得到很多有用的信息,非结构化数据的数据探索得到的信息有限。
仅仅能够得到字符出现的频率、次数,新闻的长度等等
先观察新闻长度
1 | train_df['text_len'] = train_df['text'].apply(lambda x: len(x.split(' '))) |
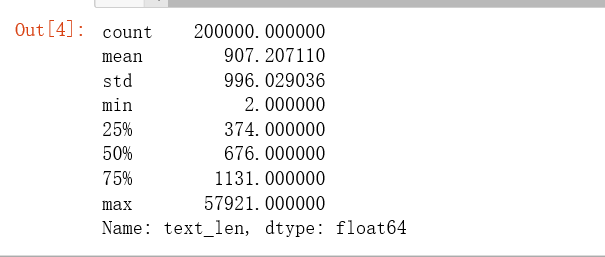
从图中可以看出,分布比较极端,但是更多的都分布在1000左右个字符
观察新闻种类数量
1 | train_df['label'].value_counts().plot(kind='bar') |
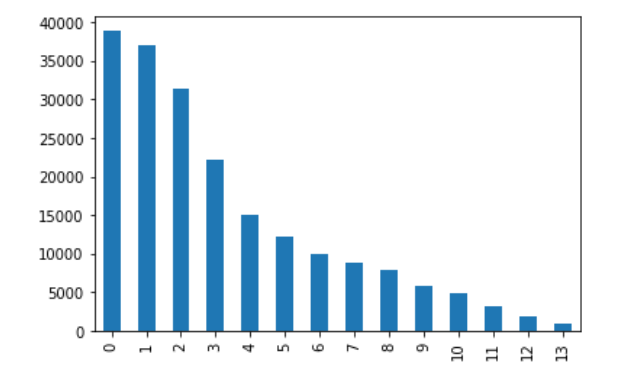
可以看出新闻类别的数量也是不均衡的,类别不均衡将会影响到模型的训练结果。
出现最多的字符
1 | from collections import Counter |
出现最多的是,‘3750’ 共出现了7482207,其次是‘648’出现了4924852,再其次是‘900’出现了3177505。并且由于这三个字符在每篇新闻中的覆盖率很高,我们有理由认为是三个标点符号。因此如果把这三个字符当作标点符号,那么,每篇新闻平均有78个句子左右。
每种新闻类别出现频率最高的字符
1 | for n in train_df['label'].unique().tolist(): |
1 | 新闻种类: 2 [('7399', 351887), ('6122', 343758), ('4939', 337756)] |